Luke Murray Kearney
Researcher at the University of Warwick
I am a final-year PhD student in Applied Mathematics at the University of Warwick. My research interests currently lie in the field of Network Epidemiology. I am developing stastical and machine learning models to reconstruct social contact networks from real-world data for use in simulation of disease outbreaks.

Research Projects
Inferring Age-Stratified Social Networks from Contact Data with Artificial Intelligence to Model Epidemics
PhD Project (2022 - Present), supervised by Dr. Emma Davis and Prof. Matt Keeling OBE
Paper: Data-Driven Construction of Age-Structured Contact Networks
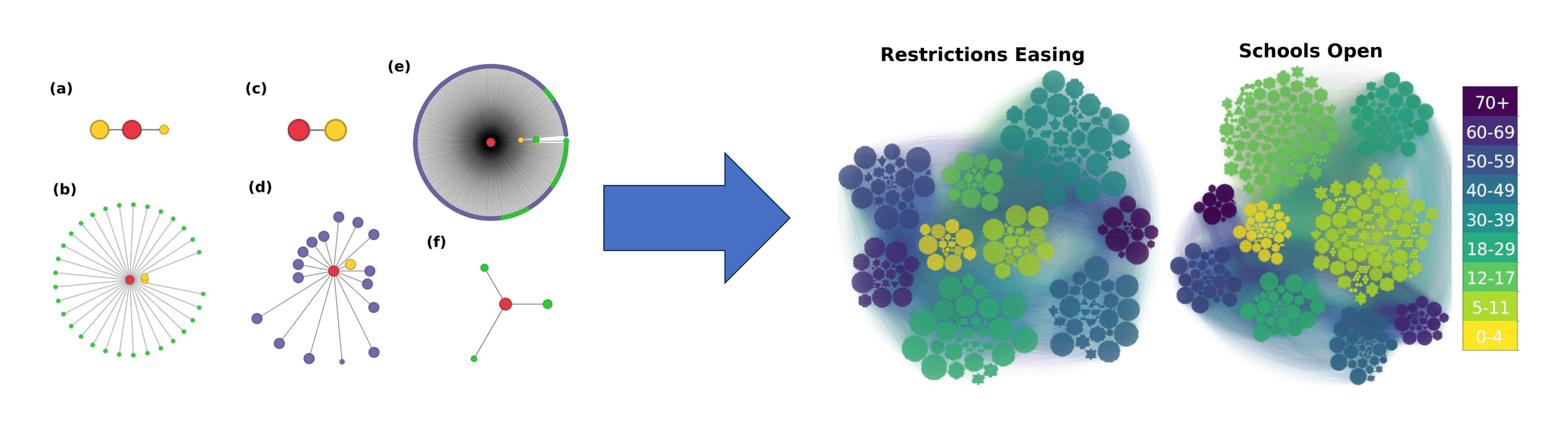
Epidemiologists often employ a well-mixed framework in their epidemic models, which assumes individuals in their population interact equally. However, contact networks have been commonly shown to be highly heterogeneous. Population heterogeneity can be difficult and expensive to accurately implement in the modelling process but its presence leads to drastically different epidemic outcomes.
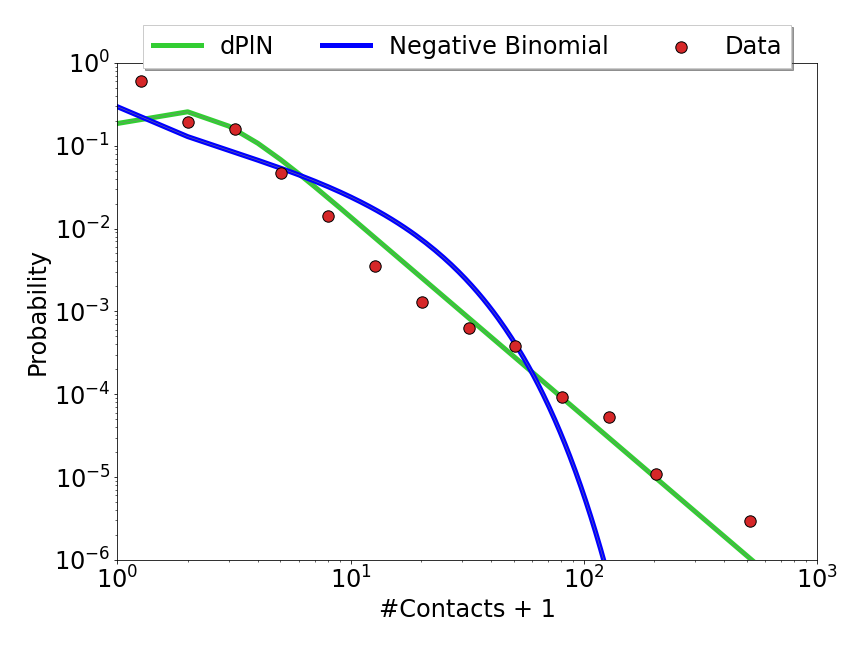
We created a standardised approach which takes routinely collected egocentric contact data and extrapolates that to a generic and robust algorithm utilizing artificial intelligence to generate a synthetic population that preserves both age-structured mixing and heterogeneity in the number of contacts. We then use these networks to simulate the spread of infection through the population, constrained to have a given basic reproduction number \(R_0\) and hence a given early growth rate. Given the over-dominant role that highly connected nodes (`superspreaders') would otherwise play in early dynamics, we scale transmission by the average duration of contacts, providing a better match to surveillance data for numbers of secondary cases. This network-based model shows that, for COVID-like parameters, including both heterogeneity and age-structure reduces both peak height and epidemic size compared to models that ignore heterogeneity. Our robust methodology therefore allows for the inclusion of the full wealth of data commonly collected by surveys but frequently overlooked to be incorporated into more realistic transmission models of infectious diseases.
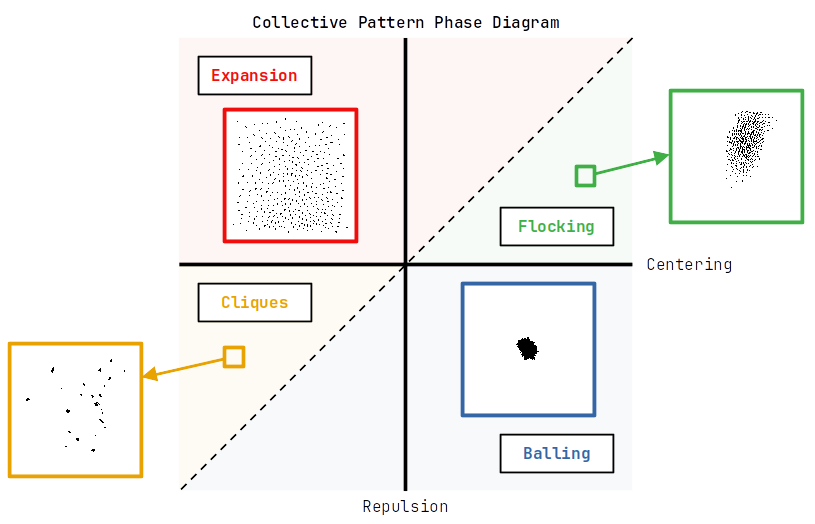
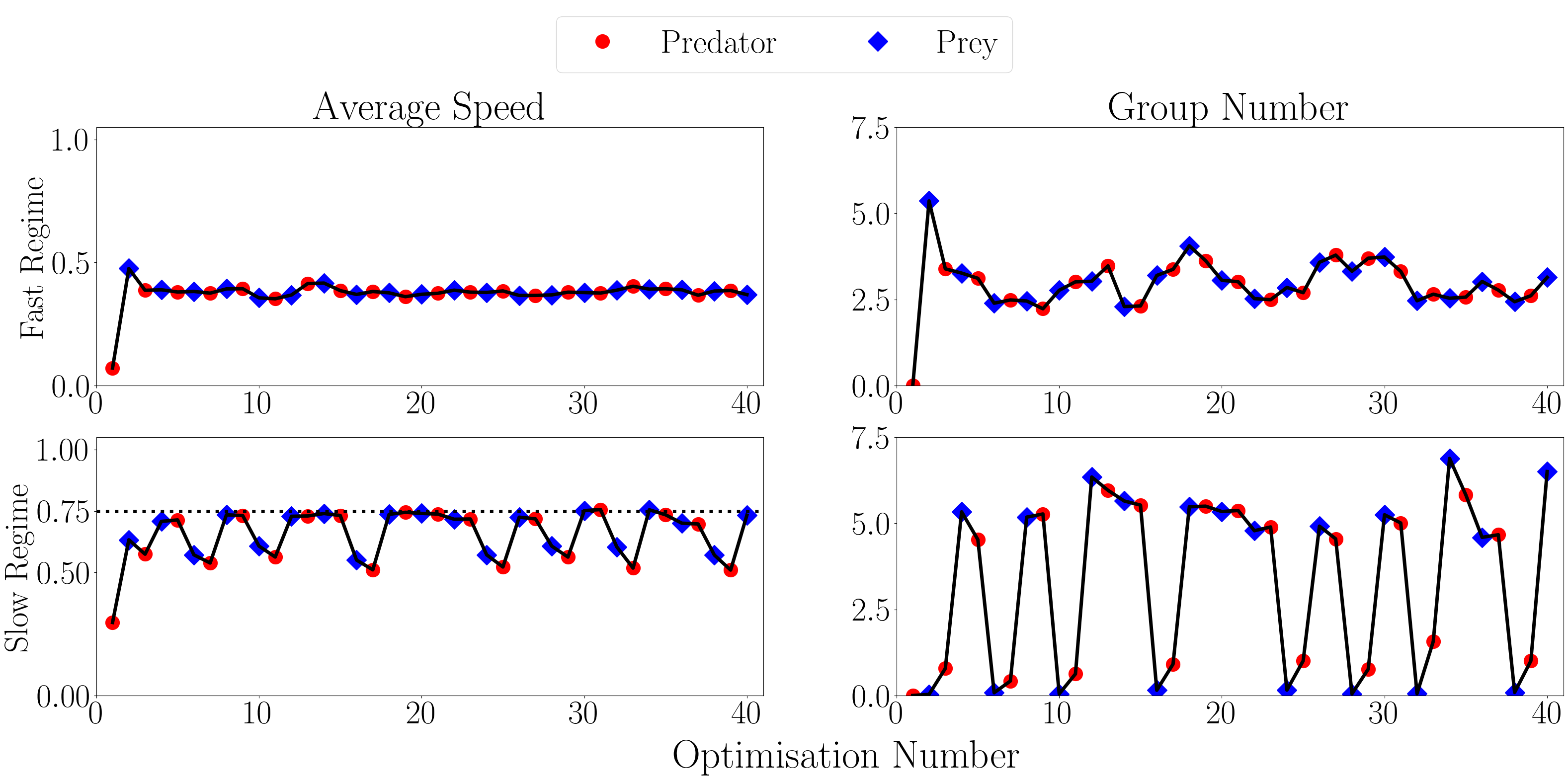
Evolving Predator-Prey Dynamics in Agent-Based Models of Collective Motion
MSc group project (Mar 2023 - Jun 2023), supervised by Dr. Gareth Alexander and Prof. Matthew Turner
Report: Evolving Predator-Prey Dynamics Paper
Viscek's seminal paper on simple force based models elicitating realistic collective motion behaviours, has given researchers a framework to analyse the drivers of real world predation. Many studies have use single predator many prey systems or vice versa, but we attempt to recreate the dynamics of lemon sharks hunt in groups close to shore through a simple force based model and evolutionary optimisation. We showed that simultaneous continuous evolution is required to recreate realistic predation tactics. Our evolutionary step process leads to cycles in predator and prey dynamics, with no dominant strategy.

We propose a bio-inspired, force-based model of agents to replicate the dynamics of a group of predators attacking a swarm of prey in a bounded space. Our model uses a first-order Euler method with a set of local metric-based interaction rules to implement a discrete time update process on a continuous space. Novel approaches to boundary conditions and predator evasion are implemented. We show that this set of simple update rules can generate complicated group chasing and evading strategies. We then implement an original evolutionary adaptation mechanism on the prey and predator behavioural parameters, to minimise or maximise the proportion of prey killed respectively. The parameter optimisation process was carried out using the BIPOP-CM-AES evolution algorithm sequentially. Optimisation resulted in continual oscillation between distinct strategies, without the emergence of a dominant strategy for either species.
How strong is the echo chamber? Examining the online discussion around the Irish Marriage Referendum
BSc Dissertation (Sep 2021 - Apr 2022), supervised by Dr. David O'Sullivan
Report: Predicting voting patterns of the Irish marriage equality referendum on Twitter.
This earlier research during my undergrad shows a nice methodology and result but the writing and graphs could be improved. Further work on this analysis could attempt to split clusters into argumentative and echo chambers to improve prediction accuracy.
We provide an examination of the mechanisms of Twitters social discourse on the 2015 Irish marriage referendum using sentiment and network analysis. Using a data set of 408,201 unique tweets this study aimed to use sentiment as an agent for homophily and to unearth political affiliation. Homophily being the tendency of members to interact at a disproportionate rate with similiar individuals. A reciprocated network, where every link in the network has at least one corresponding inversely directed link, was created and found to be much more useful for analysis of dialogue because of it's density of active users and reduction in the large inward focused hubs. We calculated sentiment scores for each tweet using a lexicographical approach to quantify emotion in text, giving a slightly positive overall sentiment centered at 1.03. Aggregation of user in and out sentiments provided us with quantitative measures of overall user emotion. Monte-Carlo simulations use single variable randomisations within a fixed topology to create a null model of random sentiments to compare our results to, which allowed us to test the significance of the empirical observations. The observations chosen are the Pearson correlation between users in and out sentiment and the fraction of both ends of a link having positive nodes in the network. Both results lie outside our confidence interval showing there is a strong positive correlation in user sentiment and the fraction of positive ends indicates homophily.

Community detection was implemented on the network to get a deeper understanding into the topological structure of the network. Further grouping of these communities using k-means clustering gives a singular partition into two clusters based on the communities respective aggregated sentiment. Two testing methods were used to quantify the relationship between the clustering and user affiliation. The first method was keyword density, finding a definite variation in relative keyword density between clusters allowing us to classify each cluster as yes or no. To evaluate the accuracy of our classification a random sample is taken of 358 voters who have been manually assigned their true voting preference, to see if our model matches the ground truth, giving an 89% balanced accuracy. A re-scaling of the variables with their respective community size is implemented. This re-scaling increased polarisation in keyword density scores and balanced accuracy to 95%. If the communities contained ideologically heterogeneous users this type of ground truth testing wouldn't be accurate. This homogeneity shows political homophily inside communities and the formation of strong echo chambers of ideologically similar individuals.
Contact
I welcome collaboration opportunities and discussions about research. Feel free to reach out for academic partnerships, speaking engagements, or general inquiries.